
Große Daten
Data Mining (Q & A)
Data Mining
Data Mining nutzt Erkenntnisse aus den Bereichen der Informatik, Statistik und Mathematik, um rechnergestützte Analysen von Datenbeständen durchzuführen. Mithilfe von Verfahren der Künstlichen Intelligenz (KI) können Querverbindungen, Muster, Trends und Zusammenhänge untersucht und somit die Entscheidungsfindung im Unternehmen erleichtert werden. Data Mining liefert Hinweise, wie Unternehmen z. B. mehr Umsatz erzielen oder Kosten einsparen können.

Was ist Data Mining?
Das Ziel von Data-Mining-Analysen ist es, Theorien zu erstellen, mithilfe dieser Aussagen über die Zukunft getroffen werden können. In diesem Bereich gibt es verschiedene Methoden, die jeweils definierten Zielen und Aufgaben zugeordnet sind. Die Aufgaben lassen sich in verschiedene Einzelbereiche aufteilen:
Abhängigkeitsanalyse: Mit der Abhängigkeitsanalyse lassen sich Beziehungen bzw. Abhängigkeiten zwischen einzelnen Merkmalen eines Objekts oder zwischen verschiedenen Objekten identifizieren.
Prognose: Eine Prognose ist die Vorhersage von bisher unbekannten Merkmalen basierend auf zuvor gewonnen Erkenntnissen und anderen Merkmalen.
Klassifikation: Die Klassifikation ordnet einzelne Datenobjekte bestimmten Klassen zu. Mit Entscheidungsregeln wird die Zuordnung festgelegt und auf bestimmte Objektmerkmale angewendet.
Abweichungsanalyse: Diese Analyse identifiziert Objekte, die den Regeln der Abhängigkeit anderer Objekte nicht entsprechen.
Segmentierung: Hierbei werden Objekte mit gemeinsamen Merkmalen zu Gruppen zusammengefasst.
Für diese Methoden verwendet Data Mining Algorithmen aus der Statistik und Verfahren der KI. Aufgrund der immer weiter entwickelten Technologien und Fortschritte in dem Bereich kann Data Mining immer bessere und genauere Ergebnisse mit höherer Relevanz liefern.
Methoden und Techniken
Es gibt sehr viele verschiedene Methoden, Techniken und Algorithmen, um Muster in Datenbeständen zu finden. Diese Methoden kommen aus der Statistik oder dem maschinellen Lernen. Außerdem werden oft interaktive Analysen mittels Visualisierungsmethoden verwendet. Hier ist ein Ausschnitt solcher Methoden zusammengestellt:
Zeitreihenprognose,
Faktorenanalyse,
Verbindungsanalyse,
Entscheidungsbäume,
Regressionsmodelle und
neuronale Netze.
Webinar: Künstliche Intelligenz – Grundlagen und Best Practices Sie möchten gerne mehr zum Thema Künstliche Intelligenz erfahren und wie Ihr Unternehmen davon profitieren kann? In unserem Webinar fassen wir Ihnen die wichtigsten Aspekte zusammen!
Data Mining und Big Data
Häufig werden die Begriffe Data Mining und Big Data gleich verwendet, obwohl die Begriffe jedoch sauber voneinander getrennt werden müssen. Big Data beschreibt große Datenmengen, die sich mit herkömmlichen Tools nicht effizient in einem angemessenen zeitlichen Rahmen verarbeiten lassen. Data Mining hingegen kommt zwar häufig bei großen Datenmengen zum Einsatz, ist jedoch nicht nur auf Big Data beschränkt. Data Mining kann auch bei kleinen Datenmengen zum Einsatz kommen, da es sich mit dem eigentlichen Vorgang der Gewinnung von Erkenntnissen aus den vorliegenden Daten beschäftigt.
Anwendungsbeispiele Data Mining
Data Mining kommt bereits in vielen Bereichen zum Einsatz und bietet in der Zukunft große Anwendungspotenziale:
Marketing und Customer Relationship Management (CRM): Mit am häufigsten wird Data Mining im Marketing und im Customer Relationship Management eingesetzt, da Unternehmen in diesen Bereichen über umfangreiche Datenbestände verfügen. Um Kundenbeziehungspflege zu betreiben, werden beispielsweise die Kundendaten mithilfe von Data Mining gruppiert.
Pharmaindustrie: Die Entwicklung von Medikamenten wird mithilfe von Data Mining erheblich verbessert. Wissenschaftler arbeiten bereits daran, mithilfe von Data Mining herauszufinden, warum Medikamente bei manchen Menschen wirken, bei anderen jedoch nicht.
Handel: Im Handel wird Data Mining genutzt, um das Kaufverhalten der Kunden mithilfe einer Warenkorbanalyse zu untersuchen. Zum Beispiel kann ein Supermarkt feststellen, dass 80 % der Frauen zwischen 25 und 35 Jahren beim Einkauf einer Zeitschrift auch gleichzeitig Snacks kaufen, wodurch die zielgruppenspezifische Werbung und die Produktplatzierung optimiert werden können.
Banken und Versicherung: Banken und Versicherungen nutzen Data Mining, um das Kaufverhalten von Kunden zu analysieren und zwischen zahlungsfähigen und zahlungsunfähigen Kunden zu unterscheiden. Somit wird das Verfahren für die Risikoanalyse genutzt.
Die Bonitätsprüfung
Ein weiteres Beispiel für Data Mining ist die Bonitätsprüfung. Die Aufgabe der Bonitätsprüfung ist die Beschaffung und Verarbeitung von Informationen zur Bestimmung des Bonitätsrisikos. Dies ist der Wert für die Wahrscheinlichkeit einer Kreditrückzahlung. Neben traditionellen Kreditprüfungen durch Sachbearbeiter werden heutzutage statistische Verfahren aus den Bereichen der künstlichen Intelligenz und des maschinellen Lernens angewendet, um Bonitätsprüfungen durchzuführen. Ausgehend von erfassten Attributen soll ein Kunde oder eine Firma einer vorgegebenen Bonitätsklasse zugeordnet werden. In der Vergangenheit abgewickelte Kreditfälle bilden dabei die Basis zur Konstruktion entsprechender Klassifikatoren, denn hier sind Informationen über die Attribute und Bonitätsklasse verfügbar. Mithilfe von Data Mining kann so zwischen guten und problembehafteten Kreditarrangements unterschieden werden.
Die Sonderform des Data Minings: Text Mining
Text Mining ist eine Sonderform des Data Minings. Das Verfahren des Text Minings ähnelt dem des Data Minings – Text Mining wird jedoch auf unstrukturierte Textdaten angewandt. Somit lässt sich Wissen aus Textdaten extrahieren. Anwender bekommen z. B. automatisch die Kernaussagen von Texten geliefert. So können Fachartikel nach spezifischen Informationen untersucht werden, die für bestimmte Projekte relevant sind.
Websession: Data Mining Sie haben Fragen zu KI-Technik und möchten es in Ihrem Unternehmen integrieren? Vereinbaren Sie eine kostenlose Websession mit uns. Ich freue mich auf den Austausch mit Ihnen.
Websession zum Thema: Data Mining × Bitte hinterlassen Sie uns Ihren Namen und die Kontaktdaten. Dann melden wir uns bei Ihnen.
Probleme
Aus den Zielsetzungen des Data Minings ergeben sich häufig sehr große Lösungsräume, die zusammen mit komplexen Algorithmen zu langen Laufzeiten führen. Außerdem wird die komplett autonome Extraktion von Mustern aus Datenbeständen häufig kritisiert, da Anwender oft keine Kenntnisse über das Umfeld haben und so Zusammenhänge und die Verwendung der gewonnen Informationen schwer zu identifizieren sind.
Auch der Schutz der persönlichen Daten vor Missbrauch und Diebstahl muss hier oberste Priorität haben. Daten müssen vor Angriffen geschützt sowie die DSGVO (Datenschutzgrundverordnung) eingehalten werden.
Zukunftsaussichten
Voraussichtlich werden zukünftige Data Mining Tools die angesprochenen Probleme reduzieren, da es zahlreiche Weiterentwicklungen in allen Bereichen von Big Data und Data Mining geben wird. Haben Sie Fragen zu diesen Themen? Wir sind Experten im Bereich der Digitalisierung und der digitalen Transformation und können Ihnen gerne weiterhelfen – kontaktieren Sie uns einfach.
Künstliche Intelligenz (KI) ist in der heutigen Zeit ein sehr präsentes Thema – besonders für Unternehmen. Mithilfe von KI können Geschäftsprozesse optimiert und effizienter gestaltet werden. Weitere Informationen zum Thema KI und über unseren Potenzialworkshop finden Sie hier.
Knowhow herunterladen ×
Data Mining Definition
Data Mining bedeutet wörtlich übersetzt so viel wie Daten schürfen. Dabei wird in der Data Mining Definition auf die Gewinnung von Wissen aus bereits vorhandenen Daten, meist riesigen Datenbeständen (Big Data) verwiesen. In diesem Artikel wird auf die Data Mining Definition eingegangen. Dabei wird nicht nur beschrieben, wie dieser Begriff definiert ist, sondern auch, wozu und wie man Data Mining durchführt. Und: Was macht Data Mining schwierig?
Sollten Sie Unterstützung bei der Erhebung oder Analyse von Daten, insbesondere im Data-Mining benötigen, helfen unsere Statistiker Ihnen gerne weiter. Nutzen Sie einfach unser Kontaktformular für eine kostenlose Beratung & ein unverbindliches Angebot – oder rufen Sie uns an.
Lassen Sie uns Ihre Anforderungen wissen & wir erstellen Ihnen innerhalb weniger Stunden ein kostenfreies Angebot.
Jetzt unverbindlich anfragen
Wozu Data Mining?
Anwendungsgebiete
Data Mining ist verbreitet in der Marktforschung, im Marketing, Vertrieb und in der Produktion, kann aber überall hilfreich sein, wo viele Daten anfallen. So zeigt beispielsweise der Vergleich verschiedener Krankenhäuser auf, welches in welchem Bereich am besten ist oder wo auch konkret Schwierigkeiten auftreten. Typische Fragestellungen, die das Data Mining behandelt, sind: Welche Produkte werden oft zusammen gekauft? (Beispielsweise: Bisquit-Tortenboden, Erdbeeren und Sahne.) Welche Faktoren sind ausschlaggebend für die Kundentreue? Gesucht werden oft auch wenn-dann-Regeln, Zusammenhänge in der Form von Entscheidungsbäumen oder Regeln in Aussagen- oder Prädikatenlogik.
Dieses Wissen unterstützt die Planung von Cross Selling, die Kundensegmentierung, die Prognose von Vertragslaufzeiten, Betrugserkennung, Business Intelligence und viele andere geschäftliche Tätigkeiten.
Data Mining Definition
Data Mining ist ein Sammelbegriff für verschiedene rechnergestützte Verfahren zur Auswertung großer Datenmengen. Dabei werden nach Data Mining Definition Hypothesen erzeugt oder Hypothesen geprüft. Das Ziel ist es, Muster und Regeln in großen Datenmengen zu entdecken, Abhängigkeiten zwischen Daten in Form von Gruppen (Clustern), Formeln, Korrelationen, Regelmäßigkeiten (Mustern) und zeitlichen Trends. Zum Einsatz kommen hier statistische und mathematische Verfahren, künstliche Intelligenz (z.B. neuronale Netze) und Visualisierungstechniken.
Durchführung
Eine 100% genaue Data Mining Definition gibt es nicht, da das Verfahren in den verschiedensten Bereichen angewandt wird.
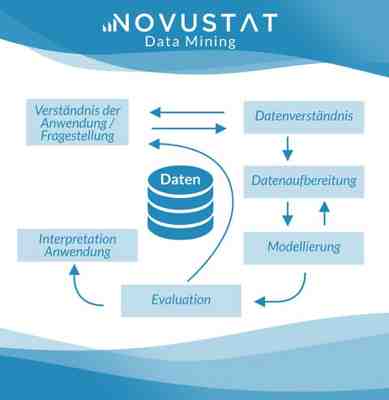
Die umfangreichen vorhandenen Datenschätze lassen sich natürlich nicht von Hand auswerten. Dazu sind Werkzeuge nötig (siehe auch unter Data Mining Software). Laut Data Mining Definition geht man folgendermaßen vor:
Vorbereitung
Im ersten Schritt definiert der Anwender sowie der Data Mining Spezialist die zu beantwortende Frage. Passend dazu erfolgt die Auswahl auszuwertender Daten. Ein Interessantheitsmaß muss definiert sein, das misst, welche Daten oder Zusammenhänge für die vorliegende Fragestellung in wie weit interessant sind.
Im zweiten Schritt des Data Mining werden die Daten zusammengeführt. Diese liegen eventuell an verschiedenen Orten (Datenbanken, Listen, Dokumente) in unterschiedlichen Formaten vor. Sie werden, beispielsweise über eine ODBC-Schnittstelle, in einem eigenen Data Warehouse oder in einer Datenbank gesammelt.
Im dritten Schritt folgt eine Datenvorverarbeitung. Dazu gehört nach Data Mining Definition insbesondere die Datenbereinigung. Manche Daten sind vielleicht doppelt (Dubletten) und werden zusammengefasst oder die Doppelten gelöscht, unplausible und widersprüchliche Daten werden gefunden und berichtigt, für fehlende Werte sollen vielleicht Schlüsselbegriffe eingetragen werden wie „na“.
Eventuell codiert der Analyst noch die Daten, z.B. Freitext bestimmten Kategorien zugeordnet werden oder Gruppen gebildet. So könnte man beispielsweise Postleitzahlen ihren Landkreisen zuordnen oder Geburtstage jeweils einer Alterskohorte.
Auswertung und Interpretation
Dann erst beginnt die Datenauswertung. Dabei spielt das Interessantheitsmaß eine wichtige Rolle. Verfahren sind u.a. Clustering, Klassifikation, Segmentierung, Extraktion, Filtern, Aggregation (Bündelung) sowie Abhängigkeitsanalysen (z.B. Korrelationsanalysen oder Regression).
Validierung: Der Data Mining Spezialist prüft die gefundenen Zusammenhänge an unabhängigen Daten, die nicht für deren Herleitung dienten. So erkennt man Gesetzmäßigkeiten, die zufällig nur in dieser einen Stichprobe existieren, aber keine allgemeine Gültigkeit haben.
Interpretation und Präsentation: Der Anwender deutet die gefundenen Zusammenhänge und anschließend erfolgt dann zumeist auch die Präsentation oder Publikation.
Was macht Data Mining schwierig?
Forschungsfrage
Die erste Schwierigkeit besteht bereits darin, die Frage richtig zu stellen. Bevor man die riesigen Datenmengen zu analysieren beginnt, sollte man ungefähr wissen, wonach man sucht. Nur so kann der Analyst die richtige Analysemethode ausgewählen. Die Forschung zum Data Mining hat gerade erst begonnen, und so gibt es erst wenige Standards, die sich durchgesetzt haben.
Rechenzeit
Selbst dann wenn der Anwender die Frage klar formuliert hat, die Data Mining Definition angewendet hat und auch die Analysemethode passend gewählt hat, tritt noch das Problem auf, dass bei großen Datenmengen zwangsläufig lange Rechenzeiten auftreten. So eine umfangreiche Auswertung kann auch Tage dauern. Viel Rechenzeit kann eingespart werden durch eine fokussierte Fragestellung und einen effizienten Auswertungsalgorithmus.
Auch die Datenqualität beeinflusst stark die Gültigkeit und Qualität der gefundenen Ergebnisse. Und die Datenqualität ist oft nicht optimal: Viele Daten fehlen, sind ungenau und wurden meist sowieso für einen ganz anderen Zweck erhoben. Insbesondere muss man gut darauf achten, mit ungültigen und fehlenden Daten richtig umzugehen, z.B. bei einer Mittelwertbildung keine fehlenden Daten als Zahlenwert 0 mit in die Berechnung einzubeziehen.
Bei der Auswertung personenbezogener Daten müssen Analysten darauf achten, aus Datenschutzgründen eine genügende Anonymisierung einzuhalten. Dabei genügt es nicht, die Namen zu löschen. Da anhand weniger persönlicher Daten wie Geburtsdatum, Geschlecht und Postleitzahl Daten wieder personenbeziehbar werden können (d.h. deanonymisiert), gehört mehr zu einer guten Anonymisierung.
Interpretation
Auch die Interpretation der durch Data Mining gefundenen Muster, Korrelationen und Trends ist nicht trivial. Ein statistischer Zusammenhang beweist noch keinen kausalen Zusammenhang. So schätzen Experten die statistische Signifikanz von Ergebnissen zuerst ab und Trends lassen sich ebenso ohne Fachkenntnis nicht einfach in die Zukunft extrapolieren.
Literatur zum Weiterlesen
Data Mining (Q & A)
Data Mining/Science-Anbieter antworten ...
Dr. Anja Moldenhauer
(Analytical Consultant der StatSoft (Europe) GmbH)
Wann sollte eine Firma Data Mining/Science Lösungen einsetzen?
Unternehmen sollten darauf achten, die im Zuge der Digitalisierung anfallenden Datenmengen zu analysieren und die Erkenntnisse zu nutzen. Dies beginnt mit einfachem Reporting, geht über komplexe Analysen für die Vorhersage des Verhaltens von Kunden oder Maschinen/Anlagen bis zur Implementierung datengetriebener Entscheidungen in operative Systemen (Schlagwort: prescriptive Analytics - anweisende Analyse). Auf Basis von Datensegmentierungen und Predictive Analytics (vorhersagende Analyse) können Sie so fundiert wichtige Business-Entscheidungen treffen. Data Mining/Science Lösungen kommen sehr gut im Zusammenhang mit folgenden Aufgabenstellungen zum Tragen:
Credit Scoring: Scoring-Modelle können entwickelt und im Produktivbetrieb eingesetzt werden
Abwanderungsanalyse: Präzise Prognosen zum Kundenverhalten und um Trends erkennen zu können
Betrugserkennung (Fraud Detection): Bewährte Predictive Analytics (vorhersagende Analyse) Methoden helfen, die entscheidenden Anomalien und Charakteristika von Schadensmeldungen zu identifizieren
Text Mining: Mit Hilfe von Text Mining finden Sie Antworten aus Informationen, die lediglich in unstrukturiertem Format zur Verfügung stehen. So haben Sie die Möglichkeit, auch bisher nicht bekannte bzw. erwartete Beziehungen zu erkennen
Risikominderung: Risiken können besser abgeschätzt werden, und entsprechende Strategien vorgeschlagen werden
Trending: Für Prozesse, die konsequent überwacht werden, kann mit Data Science Verfahren ein verbessertes Prozessverständnis erreicht werden
Predictive Maintenance: Mit Predictive Analytics (vorhersagende Analyse) können Reparatur- und Wartungsarbeiten anhand von in Echtzeit prognostizierten Ausfallwahrscheinlichkeiten terminiert werden.
Was ist der innovative Charakter ihrer Data Mining/Science-Lösung?
Mit unserer Daten-Innovationsstrategie verbessern Sie die Aktualität und den Detaillierungsgrad der bestehenden Datenbasis kontinuierlich. Komplementäre Analysemethoden steigern Qualität, Umfang sowie Kosteneffizienz der Datenanalyse und reduzieren gleichzeitig Ihren Aufwand. Selbstverständlich berücksichtigen wir wichtige Regelungen zu Datenschutz, Datensicherheit und Data Governance, wenn wir Ihre Daten-Innovationsstrategie umsetzen.
StatSoft setzt seit vielen Jahren Daten-Innovationsprojekte um und führt analytische Plattformen ein. Die Data Mining Projektmethode CRISP-DM liefert dabei die Basis für unsere Daten-Innovationsprojekte. Die Methode beschreibt die sechs Projektphasen: Geschäftsverständnis, Datenverständnis, Datenvorbereitung, Modellierung, Evaluierung und Bereitstellung.
Wo sehen sie Data Mining/Science in fünf Jahren?
Die Relevanz und der Nutzen durch Data Mining/Science wächst kontinuierlich. Data Mining/Science wird ein fester Bestandteil in vielen Branchen sein und immer entscheidender für den Geschäftserfolg. Es wird eine Demokratisierung von Analytik sattfinden. Somit werden nicht nur die „großen Firmen“ auf Datenanalyse setzen, sondern der Gebrauch von geeigneten predictive Analytics (vorhersagender Analyse) Tools wird sich noch weiter nach unten in die mittelständischen und kleinen Unternehmen ausweiten und hier einen großen Nutzen erbringen. Viele Firmen werden ihre aktuellen datenbezogenen Verfahren überdenken und innovativere und effektivere Verfahren für ihre Datenanalyse nutzen. Hierfür muss das Verständnis geschult werden und weitere Fachkräfte entwickelt und gefördert werden.